Matlab
Matlab Simulink
Simulink NS3
NS3 OMNET++
OMNET++ COOJA
COOJA CONTIKI OS
CONTIKI OS NS2
NS2
What is a spark in big data analytics? The framework of Apache spark is similar to the outline of Hadoop and it is used to provide several interconnected standards, systems, and platforms and which is considered the finest advantage for apache spark projects for students.
What is apache spark used for?
Apache spark is the distributed processing and open source system and it is deployed for big data workloads. It makes use of optimized query execution and memory caching and the implementation of optimized query which is applicable for all the data sizes. In large-scale data processing, Spark is considered the fastest and the most wide-ranging engine.
Is apache spark database?
Apache spark can process the data that belongs to various data repositories. It consists of relational data stores, Hadoop distributed file systems (HDFS), and NoSQL databases. In addition, Apache Hive is considered the foremost example. The spark core engine is using the resilient distributed data set (RDD) and it is the fundamental data type.

Apache spark main component
The following components are important in implementing Apache spark projects for students…
- Graphx
- Spark is used to originate the libraries for the manipulation of computation performance and graph databases are denoted as GraphX
- It is used to combine the iterative graph computation, exploratory analysis, and ETL process (extract, transform, and load) in the single system
- MLlib (machine learning )
- Through cluster, spark scale is assisting all the functions
- The machine learning library is utilized for the preparation of Apache spark
- It includes collaborative filtering, regression, clustering, a wide array of machine learning algorithms classification, etc.
- It consists of various tools for evaluating, tuning, and constructing the machine learning pipelines
- Spark SQL
- Spark SQL is one of the modules in Apache spark that is functioning in structured data
- It offers the spark with additional data about the structural design of the computation and data through the interfaces
- Apache spark core
- In the spark platform, the Spark core is considered the common and wide-ranging engine and is used for all the functionalities
- In the external storage system, it is the provision of referencing datasets and in-memory computing
- Spark Streaming
- The processed data with the utilization of complex algorithms that are strapped through the file system, live dashboards, and databases
- Components that permit spark for the real-time data streaming process
- In addition, the data is consumed through various sources such as
- Hadoop distributed file system
- Kafka
- Flume
What does spark do for you?
Spark is supportive of the interpretation of computational (apache big data projects)and challenging tasks for processing a huge volume of data in real-time.
Features
-
- Better analytics
- Real-time processing
- Flexibility
- Fast processing
- In memory computing
- Better analytics
-
- Apache spark includes the process such as
- Complex analytics
- SQL queries
- Machine learning algorithms and more
- So, it is in contrast with the MapReduce process because that consist of two functions such as
- Map
- Reduce
- The above-mentioned features based on analytics are used for the finest performance in spark
-
- Real-time processing
- Spark has the capability for the process in real-time data streaming
- In addition, it is oppositely functioning to MapReduce because it can process the stored data
- But, the spark can process the real-time data and it makes immediate results for the process
- Flexibility
- In general, apache spark is processing to assist in various languages and that permits the developers to write applications for the languages such as
- Python
- Java
- R
- Scala
- In general, apache spark is processing to assist in various languages and that permits the developers to write applications for the languages such as
- Fast processing
- Big data is categorized into veracity, volume, velocity, and variety for the required speed processes
- Spark includes a resilient distributed dataset (RDD) and this is used to reduce the time for the operations such as writing and reading
- It is faster than the Hadoop
- Apache spark technology is selected for its speed of functioning
- In memory computing
- RAM of servers is the location where Spark used to store the data and it permits the users for quick access to all the analytics process
Handling a large set of data
- Apache spark
- Spark is enhanced with its efficiency of computation and speed by storing the data in memory instead of storing in the disk
- Hadoop MapReduce is drifted with the size of data is turned too huge and that creates an issue in RAM
Getting started with Apache Spark Projects for students (Guide)
Spark is become familiar due to its functions of organizing the datasets in memory. Downloading and unpacking are considered the initial steps in Spark. The downloading section is started through the following process
- The package type namely “Pre-built for Hadoop 2.7 and later” is selected and the users have to click the “Direct Download”. The compressed file will be downloaded
- The imitation of the Hadoop environment is essential for windows users. The user has to follow the steps such as
- The machine has to install the Java development kit
- Then the user has to create the local directory
- C:\spark-hadoop\bin\
- Windows binaries are copied for Hadoop
- exe
- HADOOP_HOME is the environment variable that is added and the winutils.exe location is used to set the values
The user has to run an interactive session with various command shells before starting the process with Spark.
- The shell prompt will be appeared through selecting the Spark bin directory and “spark-shell” is the command which is used to start up the shell
Additional language bindings
- Kotlin – Kotlin for Apache Spark
- Groovy – groovy-spark-example
- Julia
- jl
- Clojure
- clj-sparl
- Geni
- A Clojure data frame library is functioning on Apache Spark by paying more attention in process of REPL experience optimization
- C# / .NET
- Mobius: C# and F# language binding and extensions to Apache Spark
Demo: Big data analytics projects with Apache Spark
- Big data analysis of campus card based on Spark
- Data mining and the adaptation of statistical campus cards are the sources for data collection and it is for the data analysis process
- The outline of spark is used for data computation with consumer queries related to the data mining computation and Spark SQL through the K-Means operation
- Aim and Objective
- The data computation from campus card using big data analytics are used to enhance the efficiency of functions with its fundamental data mining and statistical methods
- Big data analytic processing with Hadoop MapReduce and spark technology
- The parallel process of huge volume data analysis with various nodes is called Hadoop MapReduce
- In addition, MapReduce has two functions as Map and Reduce, and the Hadoop file distributed system is used to store the huge data
- Spark is created to fill all the gaps in MapReduce and it is used to run the real-time data
- Aim and objectives
- The Spark is used for the functions such as
- Implementation of the directed acyclic graph engine
- Resilient distributed datasets
- Structural design of spark and Hadoop MapReduce are functioning for further tasks
To this end of the article “apache spark projects for students,” we declare that we are ready to provide flawless research assistance were starting from the topic selection to the project submission.
Subscribe Our Youtube Channel
You can Watch all Subjects Matlab & Simulink latest Innovative Project Results

Our services
We want to support Uncompromise Matlab service for all your Requirements Our Reseachers and Technical team keep update the technology for all subjects ,We assure We Meet out Your Needs.
Our Services
- Matlab Research Paper Help
- Matlab assignment help
- Matlab Project Help
- Matlab Homework Help
- Simulink assignment help
- Simulink Project Help
- Simulink Homework Help
- Matlab Research Paper Help
- NS3 Research Paper Help
- Omnet++ Research Paper Help
Our Benefits
- Customised Matlab Assignments
- Global Assignment Knowledge
- Best Assignment Writers
- Certified Matlab Trainers
- Experienced Matlab Developers
- Over 400k+ Satisfied Students
- Ontime support
- Best Price Guarantee
- Plagiarism Free Work
- Correct Citations
Expert Matlab services just 1-click

Delivery Materials
Unlimited support we offer you
For better understanding purpose we provide following Materials for all Kind of Research & Assignment & Homework service.
 Programs
Programs Designs
Designs Simulations
Simulations Results
Results Graphs
Graphs Result snapshot
Result snapshot Video Tutorial
Video Tutorial Instructions Profile
Instructions Profile  Sofware Install Guide
Sofware Install Guide Execution Guidance
Execution Guidance  Explanations
Explanations Implement Plan
Implement Plan
Matlab Projects
Matlab projects innovators has laid our steps in all dimension related to math works.Our concern support matlab projects for more than 10 years.Many Research scholars are benefited by our matlab projects service.We are trusted institution who supplies matlab projects for many universities and colleges.
Reasons to choose Matlab Projects .org???
Our Service are widely utilized by Research centers.More than 5000+ Projects & Thesis has been provided by us to Students & Research Scholars. All current mathworks software versions are being updated by us.
Our concern has provided the required solution for all the above mention technical problems required by clients with best Customer Support.
- Novel Idea
- Ontime Delivery
- Best Prices
- Unique Work
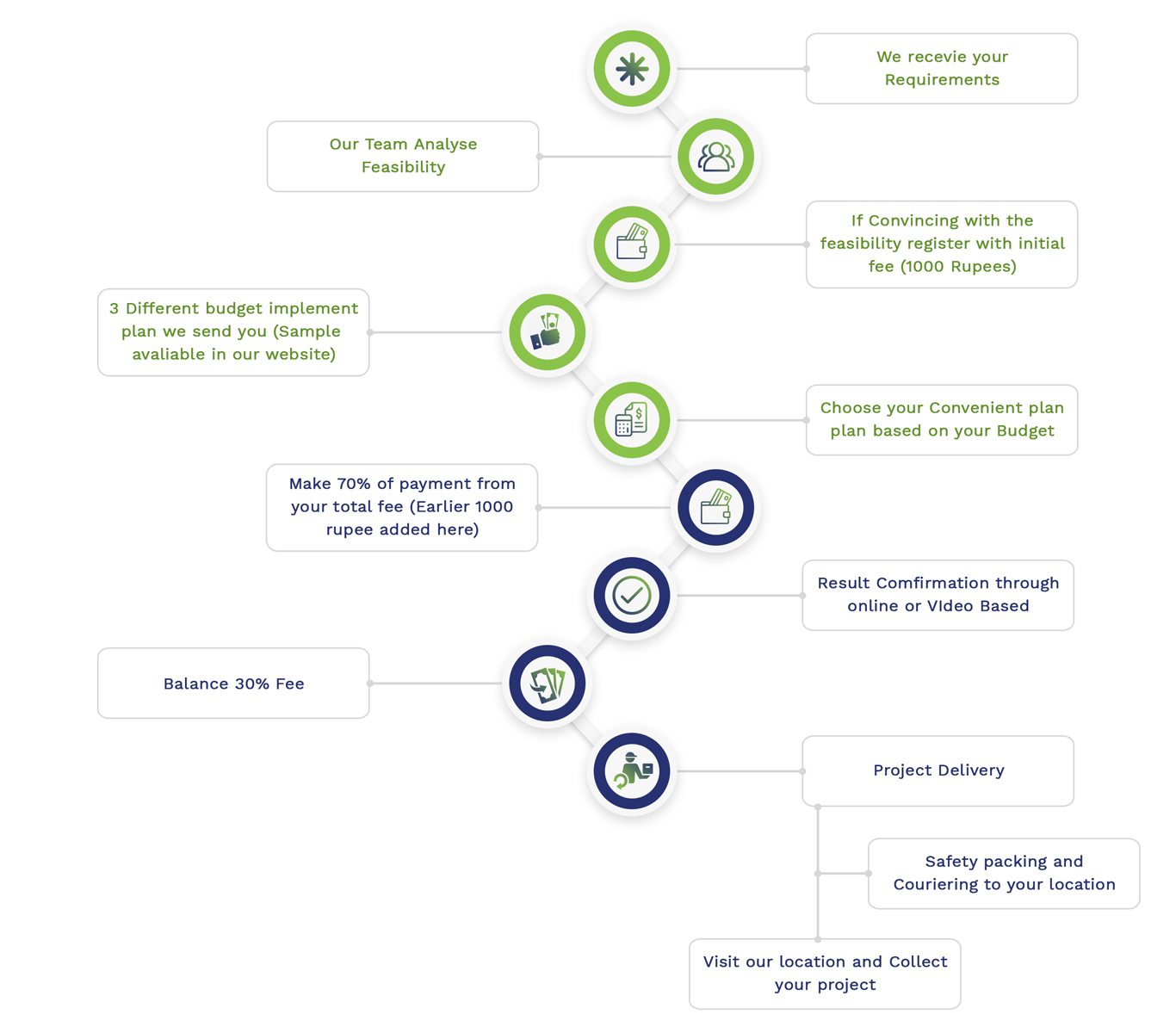
Simulation Projects Workflow
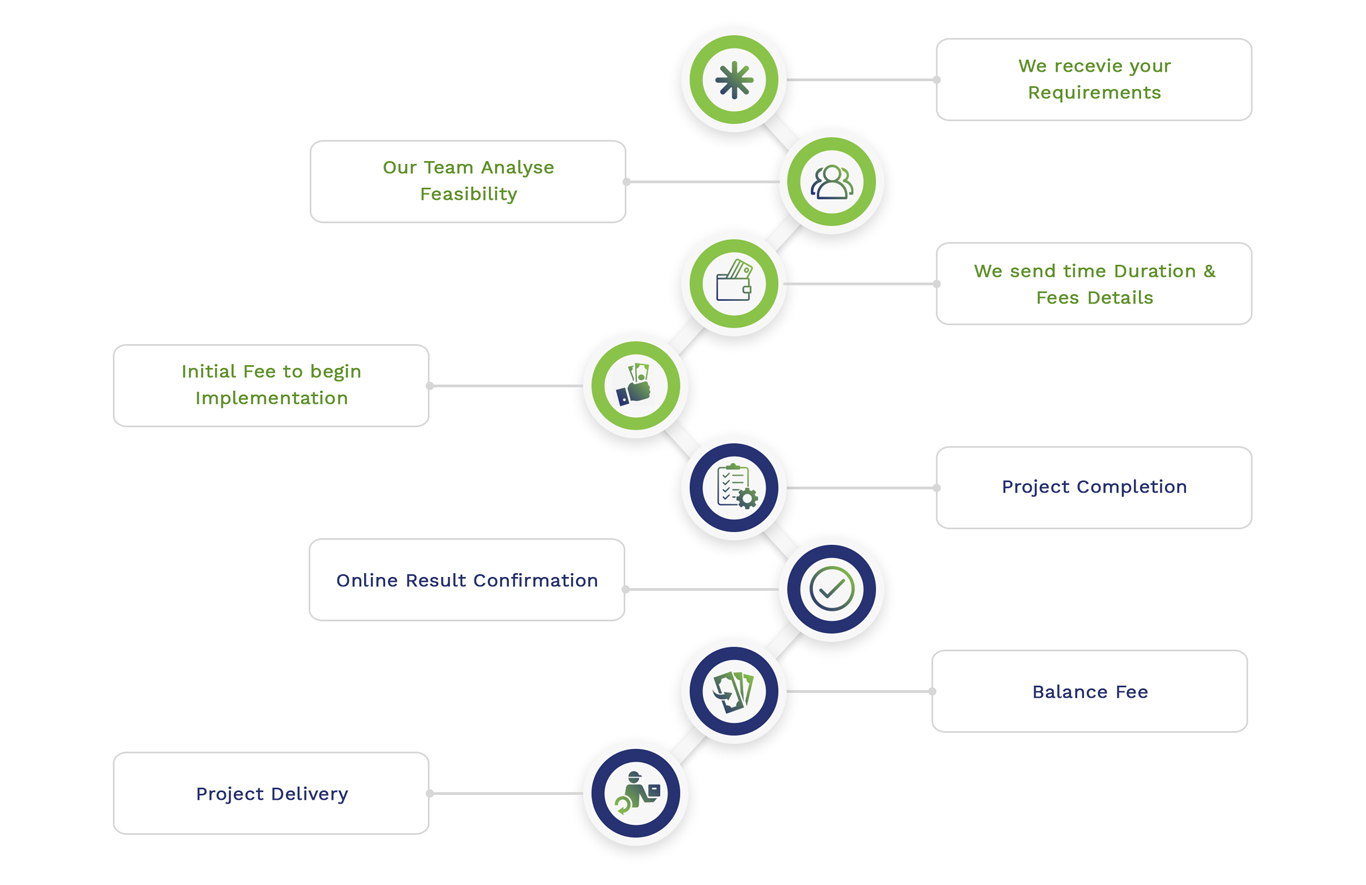
Embedded Projects Workflow